NCBI - WWW Error Blocked Diagnostic
어텐션 기법 및 의료 영상에의 적용에 관한 최신 동향
딥러닝 기술은 빅데이터 및 컴퓨팅 파워를 기반으로 최근 영상의학 ...
www.ncbi.nlm.nih.gov
⇒ 두 Attention의 가장 큰 차이점은 생성되는 attention map의 형태에 존재한다.


Hard Attention
- attention map이 중요 특징영역은 1로 설정하고, 나머지 부분은 0으로 구성되는 이진 형태
- Processing process에서 메모리 사용량을 효과적으로 줄일 수 있지만, 미분이 되지 않아 일반적인 딥러닝의 역전파 알고리즘으로는 학습할 수 없고 강화 학습 (reinforcement learning)과 같은 좀 더 까다로운 방법으로 학습해야 한다.
- hard-attention은 주로 이미지 분야에 사용된다.
- hard-attention을 사용하게 되면 attention-weight 값을 직접 계산하지 않고 확률적으로 샘플링하여 사용하는 부분이 있기에 미분이 불가능해진다. (역전파를 위한 loss 사용에 유의)
[자세히는 들여보지 않았음]
필요시 위의 논문을 통해 확인
Soft Attention
- 미분이 가능함
- hard attention보다 많은 메모리와 계산을 요구
- 생성 과정에 있어 미분이 가능하여 deep learning model과 함께 역전파 알고리즘으로 쉽게 end-to-end 학습이 가능하다.
- attention map 전반에 걸쳐 값이 존재하되 중요 영역의 값이 나머지 영역에 비해 훨씬 큰 값을 갖는다.
좌 = hard attention , 우 = soft attention
최근에는 spatial dimension을 따라 표현되는 attention과 다르게 deep learning model 내 feature map의 채널 축을 따라 표현되는 channel-wise attention 기술도 각광 받고 있다.
Channel Attention
⇒ 관련 논문 = Sqeeze-and-Excitation Networks0
먼저 GAP(Global Average Pooling)을 사용해서 데이터들을 채널별 요소로 변경시킴
Excitation
- 해당 부분에서는 채널별 의존성을 완전히 포착하는 것을 목표로 한다.
- 이를 위해서는 두 가지 기준을 충족해야 한다.
- Flexible (채널 간 비선형 상호작용을 학습할 수 있어야 함)
- 상호 배타적이지 않은 관계를 학습해야 한다.
- 하나의 채널만 활성화 하는 것이 아니라 여러 채널을 강조하고자 하기 때문
- 따라서 sigmoid activation을 사용하는 단순한 gate mechanism을 채택.
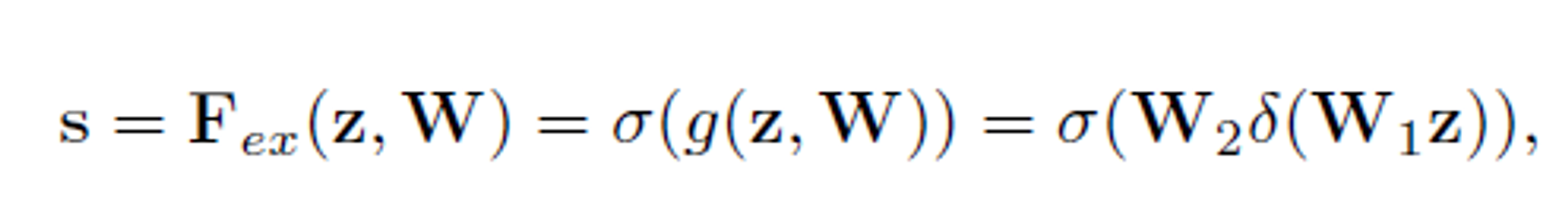
Reduction Ratio
(대충 생각해 보기로는.. 이 값은 실험을 통해 결정되는 값인 느낌인건가?)
축소 비율 r은 SE 블록의 용량과 계산 비용을 다양하게 할 수 있는 hyper-parameter이다.
이를 통해 성능과 계산 비용 사이의 균형을 조사하고자 다양한 r 값에 대한 실험을 수행한다.

위의 표를 통해 확인 가능하듯, r값이 높다고 좋은게 아님.
r = 16으로 설정하면 정확성과 complex 사이에 좋은 balance를 가질 수 있다.
실제 네트워크 전체에서 동일한 비율을 사용하는 것이 최적이 아닐 수 있다. (다른 레이어에서 수행하는 역할이 다르기 때문이다.)
→ 그럼 이거를 레이어 별로 적절하게 수행해주는 알고리즘을 만들 수는 없나??
따라서 특정 기본 아키텍처의 요구 사항을 충족하기 위해 비율을 조정함으로써 추가적인 개선이 가능할 수 있다.
'대학원 > SCI_논문 관련' 카테고리의 다른 글
| [연구 겸 공부]컴퓨팅 파워 계산 방법 (38) | 2023.12.20 |
|---|